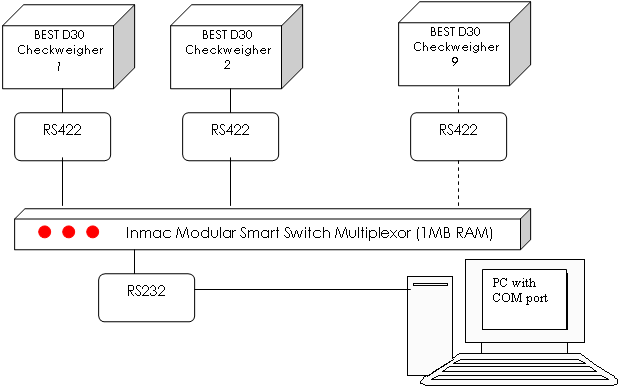
Сбор данных в Управляющей информационной системе учета добычиСбор данных в "Управляющей информационной системе учета добычи"Нам необходимо программное обеспечение, совместимое с "Управляющей информационной системой учета добычи", для автоматического сбора данных с существующих устройств учета добычи, без участия оператора. Нам необходимо, чтобы отчеты можно было просматривать и распечатывать по необходимости в любое время, по отдельности для продуктов, серий, партий, линий и временных периодов.
Мы хотели бы сохранять копию оригинальных двоичных данных, чтобы обеспечить совместимость системы с "Торговыми стандартами", и иметь возможность отслеживать все действия, и при этом перейти на безбумажный учет. Мы хотели бы помещать данные от устройств в Microsoft Access или Microsoft Excel. Обзор оборудования
Требования:
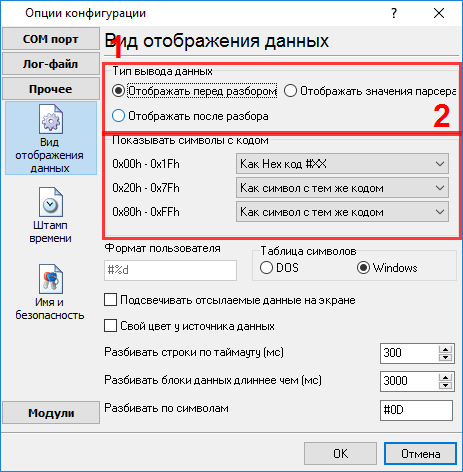
Подразумевается что: Вы настроили параметры связи с устройством (скорость, количество бит данных, контроль передачи и т.п.) в логгере и можете принимать данные без каких либо ошибок. Решение: На рисунке 1 выше виден формат данных одного из отчетов, выдаваемых системой учета. Данные содержат непечатные символы. Теперь, необходимо определить символы окончания пакета данных, по которым программа сможет выделять пакет данных из общего потока. Пожалуйста, включите вывод на экран непечатных символов, у которых код символа меньше 0x20h. Пожалуйста, установите опции с рисунка ниже. Вам необходимо создать конфигурацию для порта, если вы не сделали этого ранее, с помощью кнопки "Плюс" в главном окне программы.
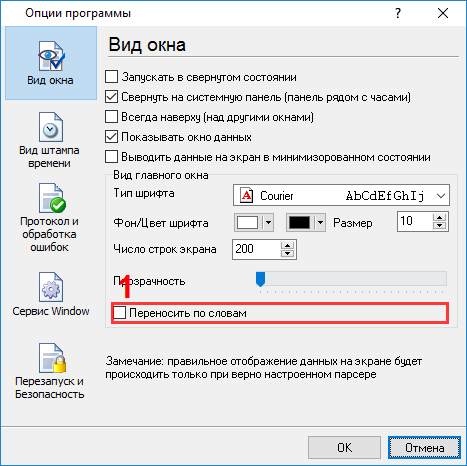
Если ваш поток данных слишком быстрый, то программа может не разбивать пакеты данных на строки, и они будут отображаться как одна длинная строка. Чтобы избежать этого, необходимо включить опцию "Переносить слова". В этом случае длина строки на экране будет равна ширине экрана (рис.4, поз. #1).
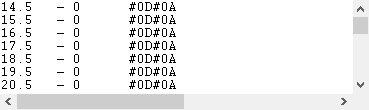
Затем кликните по кнопке "OK" и попробуйте принять данных из порта. Вы должны получить данные, как на рисунке ниже.
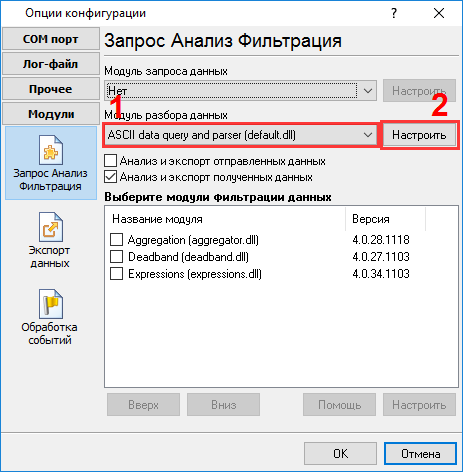
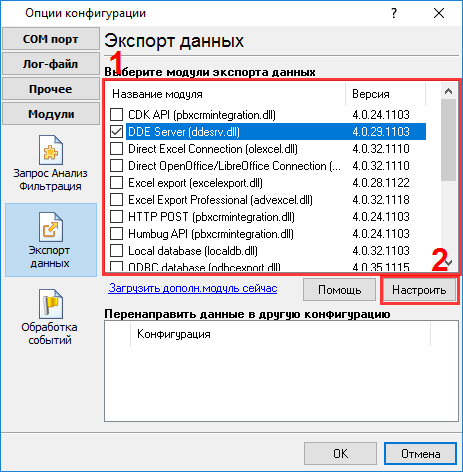
Это другой вид принятых данных. Все непечатные символы были заменены на их код вида #0D. Теперь очевидно, что пакет данных начинается с #1E#1F#1B (подчеркнуто синим) и заканчивается на #0D#0A#0C (подчеркнуто красным). В нашем случае пакет данных на экране был разбит на несколько строк, но при настройке парсера следует трактовать эти строки как единое целое. Теперь мы готовы к настройке модулей. Сначала, пожалуйста, выберите модуль "ASCII data parser and query" (рис.6a, поз.1) из выпадающего списка. Затем, включите анализ и экспорт для принимаемых данных (рис. 6a, поз. 2). Модуль "DDE server" (рис.6b, поз.3) поможет нам проверить, что парсер правильно разбирает пакет данных. После окончания настройки его можно будет отключить для экономии ресурсов. Модуль "Local database" будет экспортировать данные в файл Microsoft Excel (рис.6, поз.4).
Сейчас, пожалуйста, откройте окно настройки модуля "ASCII parser and query" (кликните на кнопке "Настроить" рядом с выпадающим списком рис.6a, поз.1). Окно настройки появится на экране (рис.7).
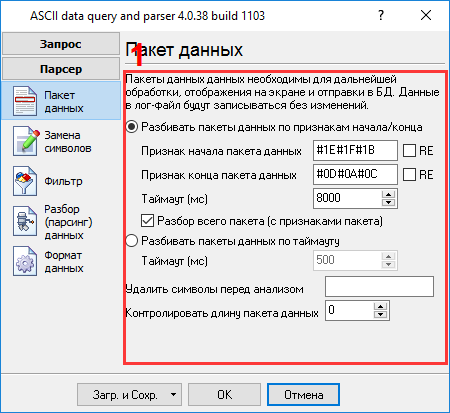
Процесс настройки должен быть простым, если предварительно был выяснен формат данных в главном окне логгера данных (рис.5). Вы должны ввести данные в том же виде, что и в главном окне программы в полях №1 и №2. Поле №1 задает начало блока данных и в нашем случае должно содержать #1E#1F#1B. Поле №2 задает окончание блока данных и в нашем случае должно содержать #0D#0A#0C. Вы должны ввести значения с рис. 3, подчеркнутые синим и красным цветами. Поскольку мы указали признаки начала и окончания пакета, то необходимо настроить значение в поле "Таймаут" (рис.7 поз.#3) для предотвращения потери данных и исключения случаев, когда был принят признак начала пакета данных, а признак окончания не был получен. Для того чтобы формировать метку даты и времени для всех отчетов, достаточно включить опцию в поле №4. Следующая закладка является очень важной частью конфигурации (рис.8). Парсер использует эти данные для того, чтобы выделить переменные из пакета данных. Наш пакет данных содержит 23 элемента (рис.1) BATCH NO, дата и время, unit no, и т.д., которые должны быть помещены в различные переменные. Далее эти переменные будут использоваться в модулях фильтрации и экспорта данных.
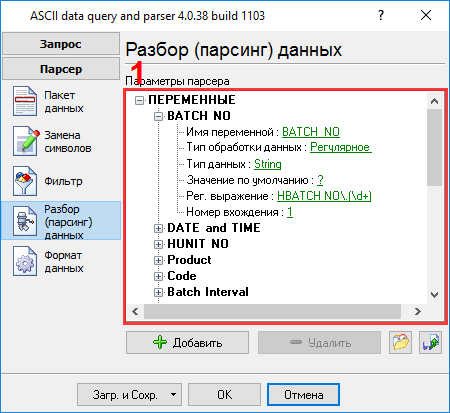
Чтобы добавить новую переменную парсера, необходимо кликнуть по кнопке "Добавить" (рис.8, поз.7). Перед добавлением переменной программа попросит ввести описание переменной. Вы можете ввести любое описание, которое поможет вам запомнить содержимое этой переменной. Мы добавили все 23 переменных с соответствующими именами и описаниями на рис.8. Полный список переменных вы можете скачать здесь и загрузить его с помощью кнопки №8 на рисунке 8. Каждая переменная парсера имеет несколько свойств:
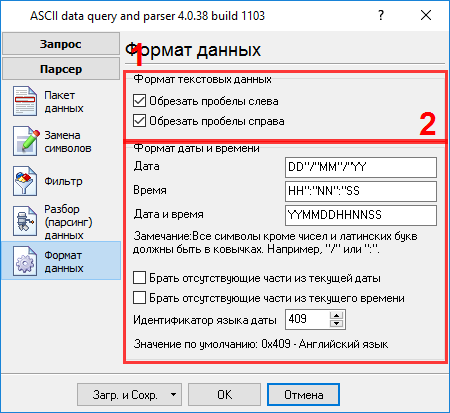
Все переменные имеют идентичные параметры, за исключением номера вхождения. На следующей закладке (рис.9) вы можете определить основные опции форматирования и преобразования значений. Поскольку мы определили тип данных "String" для некоторых переменных, поэтому первые две опции позволяют удалять пробелы в начале и конце значения. В этом примере у нас есть переменная с типом "datetime". Поэтому вторая опция позволяет определить маску, по которой строковое значение даты будет преобразовано в переменную с типом данных "datetime". Мы указали YYMMDDHHNNSS здесь, в соответствии с форматом данных на рис. 2. Для более подробного описания символов, которые могут использоваться в маске, пожалуйста, обратитесь к файлу справки.
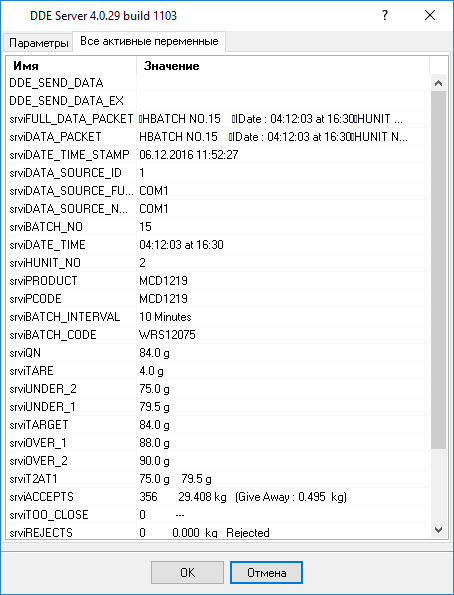
Другие опции не требуется настраивать, поскольку у нас не заданы переменные с типом "date" или "time". Пожалуйста, кликните на кнопке "OK" в окне настройки парсера и затем на кнопке "OK" в окне настройки конфигурации. Теперь наш парсер настроен и пришло время проверить его. Подсоедините ваше устройство или включите его, если это необходимо. Попробуйте принять пакет данных от устройства. Если парсер был верно настроен, то в окне DDE сервера будут отображены наши переменные и их значения (рис.10).
Теперь все переменные готовы для экспорта в базу Microsoft Access или файл Microsoft Excel. Сопутствующие статьи: Сбор данных в Управляющей информационной системе учета добычиAdvanced Serial Data Logger. Дополнительные материалы:Последовательный интерфейс RS232 разводка и сигналы Кабели и сигналы Кабели мониторинга данных |
|