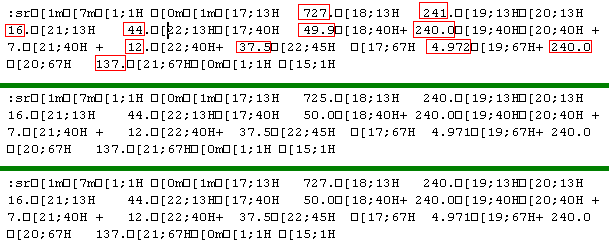
Парсинг данных с использованием регулярных выраженийЗадача: У меня есть оборудование, которое передает последовательные данные в терминальную программу (пример данных приведен ниже). Нужно извлечь значения из определенных позиций (помечены красным). Блоки данных выделены зеленым. Можно ли это сделать с помощью вашей программы? Также, хотелось бы передавать выделенные данные в Excel.
Требования:
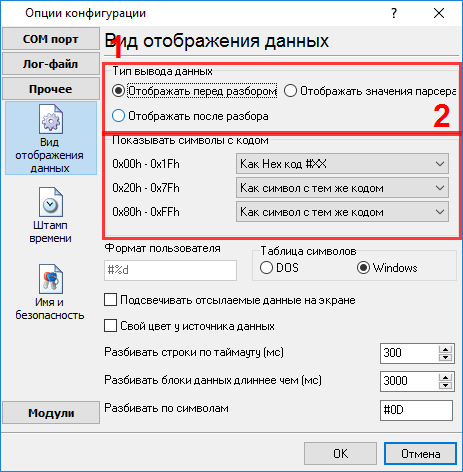
Подразумевается что: Вы настроили параметры связи с устройством (скорость, количество бит данных, контроль передачи и т.п.) в логгере и можете принимать данные без каких либо ошибок. Решение: Изображение выше демонстрирует, что поток данных содержит непечатные символы (квадратики на изображении). Поэтому на изображении не видно символов окончания пакета данных. Необходимо определить эти символы для каждого пакета данных. Необходимо включить вывод непечатных символов в виде их кода. Для этого настроим следующие опции.
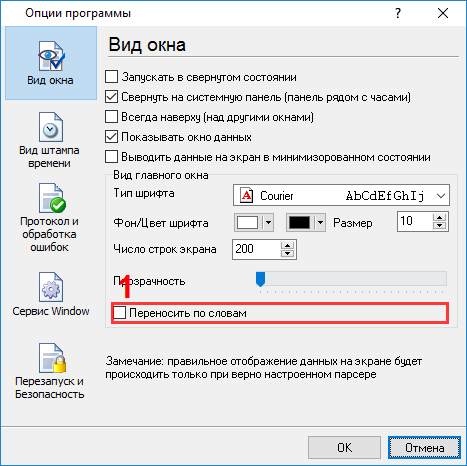
Затем необходимо включить опцию "Перенос слов" (рис.3), поскольку блок данных очень большой и не уместится в окне программы. Вы можете открыть диалоговое окно ниже, используя пункт главного меню программы "Опции - Опции программы".
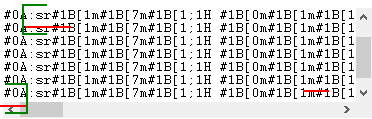
Затем кликните по кнопке "OK", для того, чтобы сохранить изменения и попробуйте принять данных из порта. Вы должны получить данные вида, как показано ниже.
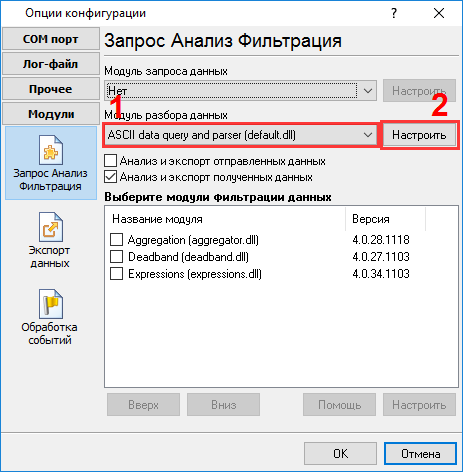
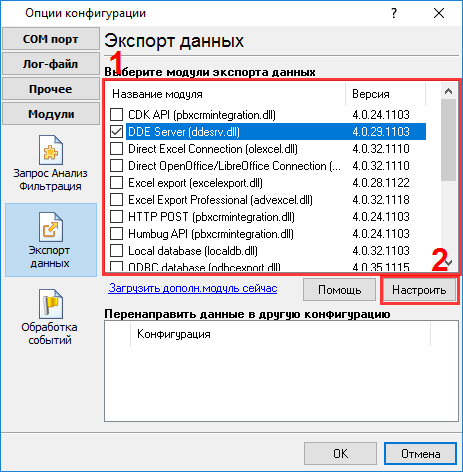
Это другой вид принятых данных. Обратите внимание, что все непечатные символы были заменены на их код вида #1B. Посмотреть на изображение выше, становится очевидным, что блок данных (в зеленых скобках) начинается с ":sr#1B" и заканчивается #0A#0D#0A (подчеркнуто красным). В этом примере, блок данных состоит их нескольких частей. Все части были разделены по ширине экрана, однако все эти части нужно интерпретировать как единое целое. Теперь мы готовы к настройке модулей. Сначала, пожалуйста, выберите модуль "ASCII data parser and query" (рис.5а, поз.1) из выпадающего списка. Затем, включите анализ и экспорт для принимаемых данных (рис. 5a, поз. 2). Модуль "DDE server" (рис.5b, поз.3) поможет нам проверить, что парсер правильно разбирает пакет данных. Модуль "Local database" будет экспортировать данные в XLS файл формата Microsoft Excel.
Сейчас, пожалуйста, откройте окно настройки модуля "ASCII parser and query" (кликните на кнопке "Настроить" рядом с выпадающим списком рис.5а, поз.1). Окно настройки появится на экране (рис.6).
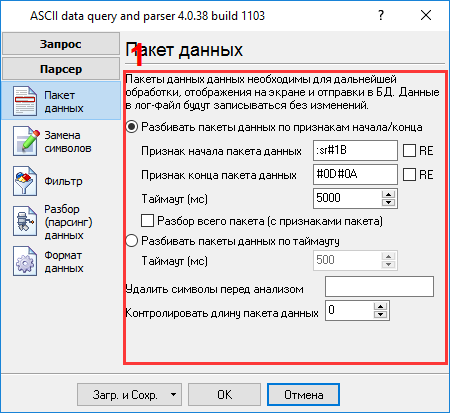
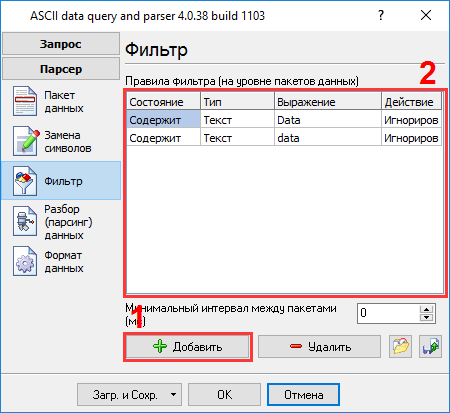
Процесс настройки должен быть простым, если предварительно был выяснен формат данных в главном окне логгера данных (рис.4). Вы должны ввести данные в том же виде, что и в главном окне программы в полях 1 и 2. Поле №1 задает начало блока данных, а поле №2 задает его окончание. Вы должны ввести значения с рис. 4, подчеркнутые зеленым. Поскольку поток данных может содержать пакеты данных, которые нам не нужно экспортировать, то мы добавили два правила фильтрации, характеризующие эти пакеты данных (рис.7). Вы можете добавить новые правила, кликнув на кнопке "Добавить". В нашем случае мы исключаем все пакеты, содержащие слова "Data" или "data" (регистр символов учитывается в поле "Выражение").
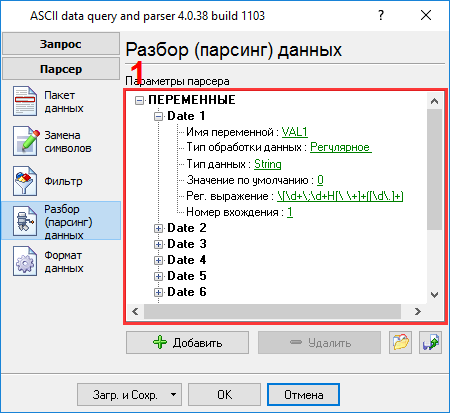
Следующая закладка является очень важной частью конфигурации (рис.8). Парсер использует эти данные для того, чтобы выделить переменные из пакета данных. Наш пакет данных содержит несколько элементов, названные как Date 1 - Date 12, которые должны быть помещены в различные переменные. Далее эти переменные будут использоваться в модулях фильтрации и экспорта данных. В нашем примере значения этих переменных будут записываться в разные колонки файла Microsoft Excel.
Чтобы добавить новую переменную парсера, необходимо кликнуть по кнопке "Добавить" (рис.8, поз.7). Перед добавлением переменной программа попросит ввести описание переменной. Вы можете ввести любое описание, которое поможет вам запомнить содержимое этой переменной. Мы добавили все 12 переменных с именами Date 1 - Date 12 с соответствующими описаниями на рис.8 Каждая переменная парсера имеет несколько свойств:
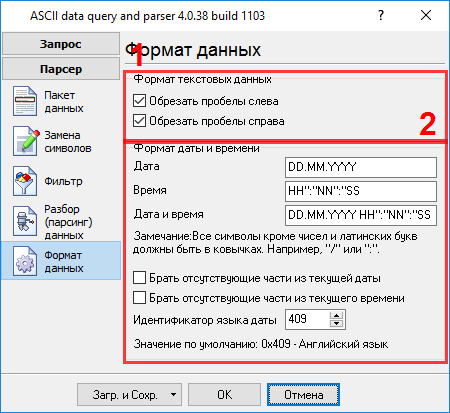
Все переменные имеют идентичные параметры, за исключением номера вхождения. На следующей закладке (рис.9) вы можете определить основные опции форматирования и преобразования значений. Поскольку мы выбрали тип данных "String" для обеих переменных, поэтому первые две опции позволяют удалять пробелы в начале и конце значения.
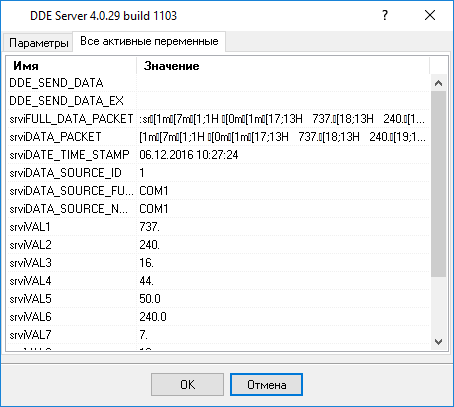
Другие опции не нужны в нашем случае, поскольку у нас нет переменных с другими типами данных. Пожалуйста, кликните на кнопке "OK" в окне настройки парсера и затем на кнопке "OK" в окне настройки конфигурации. Теперь наш парсер настроен и пришло время проверить его. Подсоедините ваше устройство или включите его, если это необходимо. Попробуйте принять пакет данных от устройства. Если парсер был верно настроен, то в окне DDE сервера будут отображены наши переменные и их значения (рис.10).
Теперь все переменные парсера готовы для экспорта в Excel. Как это сделать, описано во второй части. Сопутствующие статьи: Парсинг данных с использованием регулярных выраженийAdvanced Serial Data Logger. Дополнительные материалы:Последовательный интерфейс RS232 разводка и сигналы Кабели и сигналы Кабели мониторинга данных |
|